
Descubriendo problemas a través de la reducción del trabajo en curso
[En este artículo, abordaremos] el trabajo en curso que llevó a una startup especializada en IA a obtener ganancias de productividad en sus proyectos de aprendizaje automático.
En Sicara nos hemos centrado cada vez más en proyectos de visión por ordenador [la visión por ordenador es la ciencia que permite a los ordenadores ver, reconocer y procesar imágenes como lo haría el ojo humano].
Los algoritmos de mejor rendimiento en este campo se llaman redes neuronales, ya que imitan vagamente el funcionamiento del cerebro humano (donde cada entrada pasa a través de diferentes capas de “neuronas”) interconectadas. Para funcionar, las redes neuronales necesitan estar "entrenadas": ingerir miles de imágenes con un contenido conocido para ajustar sus parámetros internos y poder reconocer el contenido de una nueva imagen. Por ejemplo, si quiero crear un algoritmo que detecte automóviles en imágenes, primero lo entrenaré para que utilice imágenes que ya sé que contienen automóviles. El algoritmo podrá entonces determinar si una nueva imagen contiene un coche.
En proyectos de visión por ordenador, probar mejoras en los algoritmos es una tarea clave para nuestros científicos de datos, una tarea que parece inherentemente impredecible: no sabemos de antemano los resultados que obtendremos ni el tiempo necesario para entrenar un nuevo algoritmo.
Cuando empezamos a trabajar en visión por ordenador y a discutir proyectos con los miembros del equipo, parecía haber muchos problemas. Sin embargo, estos normalmente no estaban relacionados con retrasos o estándares de calidad no cumplidos. Al analizar el enfoque de nuestro equipo, dedicamos tiempo a analizar el proceso de cada nuevo experimento. Esto implica:
- Codificar el algoritmo y lanzar su entrenamiento;
- Mientras se lleva a cabo la capacitación, mantenga la tarjeta de funcionalidad en “hacer” y comience a trabajar en una nueva tarea. Esta fase de espera puede durar varios días;
- Volviendo al experimento una vez completado el entrenamiento para extraer los resultados.
Quedaba claro que tener varias tareas en progreso para cada miembro del equipo hacía difícil estimar el tiempo requerido para cada tarea y, por lo tanto, medir los problemas de productividad. Por ejemplo, después descubrimos algunas reelaboraciones ocultas: el equipo había estado trabajando en capacitaciones que habían fracasado y necesitaban ser relanzadas.
Analizamos con más detalle lo que hace un científico de datos cuando trabaja en un nuevo experimento y descubrimos que el proceso se puede dividir en cinco pasos. Para ilustrar esto, tomemos un ejemplo concreto de uno de nuestros proyectos. El equipo había estado entrenando una red neuronal llamada MaskRCNN en fotografías de superficies planas tomadas desde un ángulo, para reconocer automáticamente objetos en estas imágenes para uno de nuestro cliente (Michel). El siguiente experimento consistió en enderezar primero estas imágenes para que parecieran fotografías tomadas desde arriba y luego entrenar la red con imágenes enderezadas.
Veamos las diferentes subtareas que tuvo que realizar nuestro científico de datos:
- Codificar el preprocesamiento de las imágenes;
- Lanzar un entrenamiento de algoritmo utilizando las imágenes preprocesadas;
- Esperar a que se entrene el algoritmo;
- Recuperar los resultados de la capacitación;
- Calcular el rendimiento del algoritmo entrenado en imágenes enderezadas.
Decidimos dividir estos experimentos en dos fases: comenzar un nuevo entrenamiento (pasos 1-2) y obtener los resultados (4-5). En nuestro ejemplo, el experimento fue "Entrenar MaskRCNN en imágenes enderezadas". Dividido en dos tareas, se convirtió en:
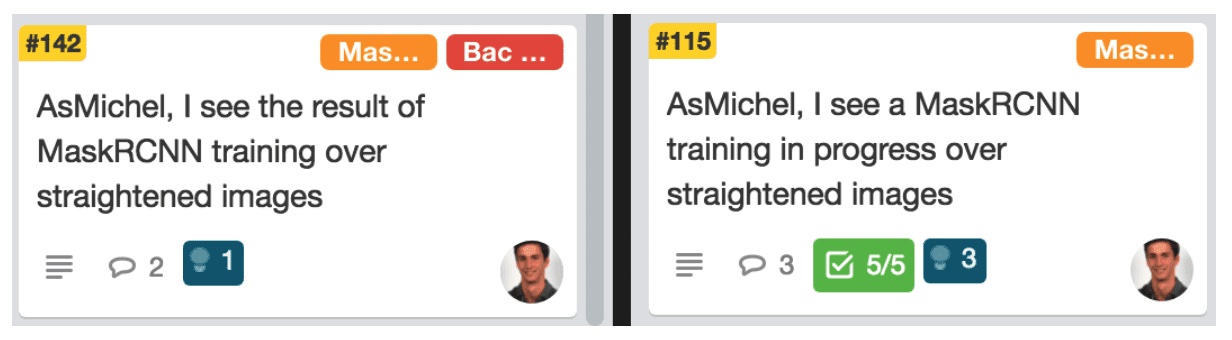
Por lo tanto, teníamos dos subtareas para cada experimento, que ahora no incluían esperas. Esto permitió a los científicos de datos estimar cada subtarea por separado, conocer con precisión el tiempo dedicado a cada una y reaccionar en caso de que una tarea tardara más de lo esperado.
Durante las siguientes seis semanas, el equipo identificó 15 casos diferentes de tareas que excedieron el cronograma planificado, en 24 experimentos diferentes. ¡Durante más de la mitad de los experimentos, una de las subtareas superó la estimación del equipo! Utilizando un enfoque de contenedor rojo, el equipo analizó cada subtarea para abordar las causas fundamentales del problema.
Permítanme compartir un ejemplo de cómo utilizamos los 5 porqués (bueno, 4 porqués en este caso) en un experimento para añadir nuevas imágenes a nuestro conjunto de datos de entrenamiento. El problema al que nos enfrentamos fue que un científico de datos tardó 1,5 horas más de lo esperado en generar las nuevas métricas de rendimiento.
- ¿Por qué? El script de análisis de rendimiento provocaba un error.
- ¿Por qué? El ordenador se quedaba sin memoria durante la ejecución del script.
En este punto, la primera acción del científico de datos fue simplemente ampliar la memoria del ordenador. Una mayor investigación sobre la tarea guardada en el contenedor rojo condujo a nuevos descubrimientos:
- ¿Por qué el ordenador se quedó sin memoria? La red neuronal se recargaba para cada imagen en la que se probaba.
- ¿Por qué? Una sola pieza de código cargaba la red neuronal y hacía los cálculos, violando una regla de codificación estándar: "Cada función realiza solo una tarea".
Aquí está el código correspondiente (ligeramente editado para simplificar):
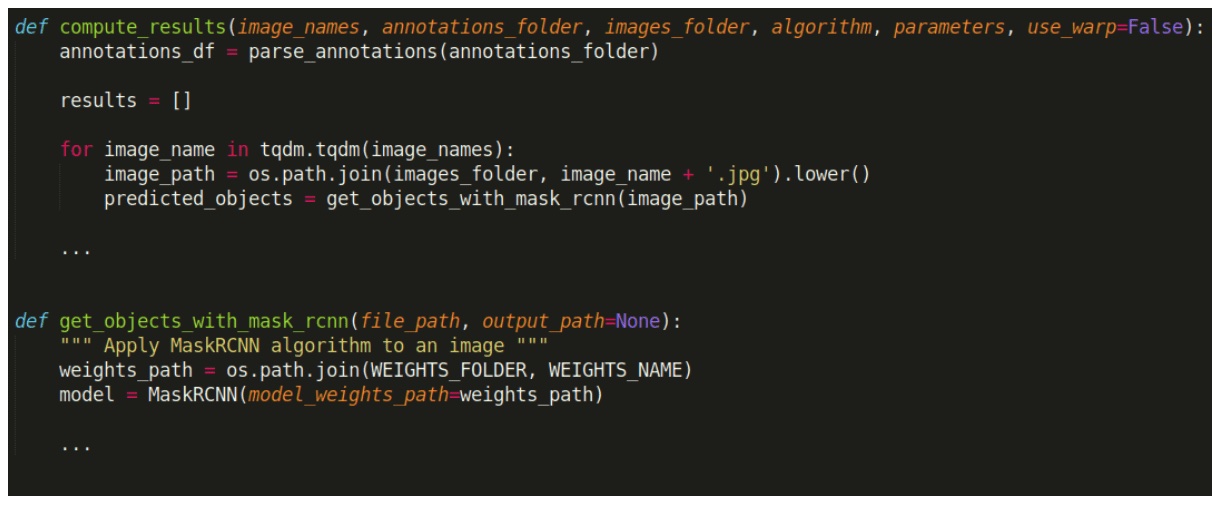
La última línea muestra que el modelo de red neuronal se recarga en la memoria dentro de una función que se supone que solo recupera los resultados, lo cual es inesperado y, como efecto secundario, aumenta el uso de la memoria.
Esta investigación condujo a mejoras en la organización de esa parte del código:
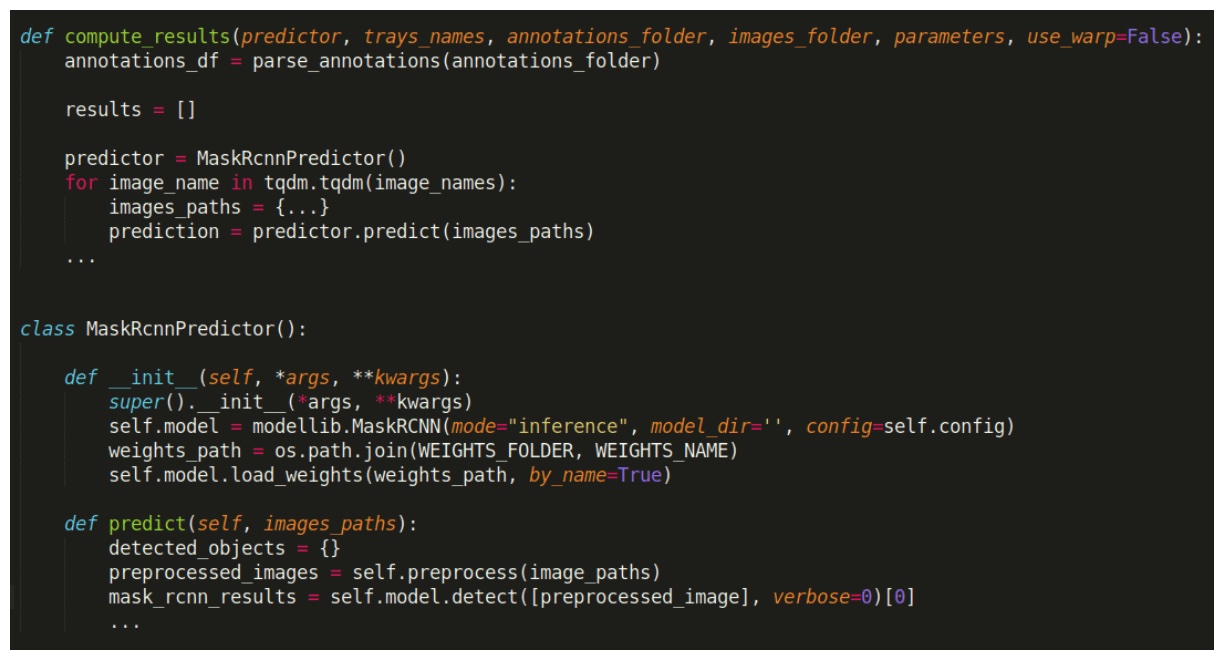
Ahora la carga del modelo ocurre en la función de inicialización (__init__), y la función de predicción solo gestiona la obtención de los resultados.
Observar las tareas agrupadas en rojo también condujo a un par de hallazgos inesperados. Al contrario de lo que pensaba, la mayoría de los problemas ocurrieron en la última etapa del experimento (determinar si las métricas de rendimiento de los algoritmos habían mejorado). Sólo tres de las 15 tareas superadas se referían a la redacción y ejecución de los algoritmos de entrenamiento.
Algunas causas comunes ya han comenzado a aparecer:
- Tres de las 15 tareas agrupadas en rojo estaban vinculadas a un entrenamiento o cálculo de métricas que debían reiniciarse después de que los servidores se quedaran sin memoria. Esto llevó a un experimento en el entrenamiento de nuestros recién llegados: añadimos un paso para poder estimar la RAM necesaria para entrenar un algoritmo determinado.
- Dos tareas terminaron en el contenedor rojo debido a conversiones incorrectas de centímetros a píxeles al calcular la distancia entre objetos. El equipo abordó este problema recurrente creando una clase de Distancia en el código que contenía ambos valores.
Dividir cada experimento en tareas más pequeñas para eliminar el trabajo en curso nos ayudó a resaltar los problemas reales que estaba teniendo el equipo. Como muestran las observaciones anteriores, analizar pequeños problemas a través de contenedores rojos puede mostrar una manera excelente (y humillante) de hacer coincidir mis ideas preconcebidas con la realidad de nuestro trabajo.
Nota del editor: Este artículo fue originalmente publicado en Planet Lean el 11 de julio de 2018.
Pierre-Henri CumengeCo-fundador Sicara, París.Extraído de: Planet Lean